

Migration of Snowflake Data Warehouse to Microsoft Fabric Using ChatGPT

Introduction
The decision to migrate from a Snowflake Data Warehouse to Microsoft Fabric can be driven by several factors including specific business needs, technical requirements, different platform capabilities, familiarity of environment, or existing heavy investments into the Microsoft technology stack.
In this guide, we will navigate through the intricacies of the migration process, leveraging the power of ChatGPT to streamline and simplify each step and make the migration seamless and efficient.
The activity is broken into two parts:
- Migrate objects
- Move or copy data
Prerequisites
Before we begin, ensure you have the following in place:
- Snowflake account
- ChatGPT free subscription/account
- Microsoft Fabric account
Part 1: Object Migration
This entry will illustrate migrating Snowflake objects, including tables, views, suser defined functions (UDFs), and SQL stored procedures.
Note: Snowflake supports stored procedures in various languages such as Java, JavaScript, Python, Scala, and SQL. However, Microsoft Fabric only supports SQL stored procedures. Additional language support may be introduced as Fabric evolves over time.
For demonstration purposes, we will consider the Snowflake sample dataset “TPCDS_SF100TCL” under the shared database “SNOWFLAKE_SAMPLE_DATA”. Let’s focus on one simple fact table (Inventory) and three dimensions (Item, Warehouse, and Date_Dim).
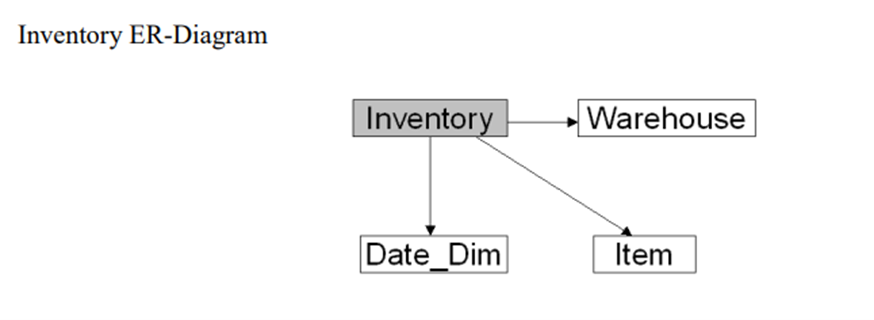
Since these four objects are part of the Snowflake Data Share, we cannot directly view the object Data Definition Language (DDLs). As a workaround, we will create a sample database, “POC_DB,” within snowflake and copy both the data and structure from the Snowflake shared database.
Migration Steps
Step 1: Create Sample Database and Copy Data
Execute the following SQL code within Snowflake data warehouse using Snowsightto prepare the data:
--create DB
create database POC_DB;
--copy 4 tables from share to EMP_DB
create or replace table warehouse as select * from SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.warehouse;
create or replace table inventory as select * from SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.inventory;
create or replace table item as select * from SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.item;
create or replace table date_dim as select * from SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.date_dim;
--Since Example database has only tables we will create one view on top of base tables & one Snowflake procedure too.
--Create view
create or replace view INVENTORY_VW as
SELECT
S_INVENTORY."INV_DATE_SK" AS INV_DATE_SK,
S_INVENTORY."INV_ITEM_SK" AS INV_ITEM_SK,
WAREHOUSE."W_WAREHOUSE_SK" AS INV_WAREHOUSE_SK,
S_INVENTORY."INV_QUANTITY_ON_HAND" AS INV_QUANTITY_ON_HAND
FROM
INVENTORY as S_INVENTORY
LEFT OUTER JOIN WAREHOUSE ON (S_INVENTORY."INV_WAREHOUSE_SK" = WAREHOUSE."W_WAREHOUSE_SK")
LEFT OUTER JOIN ITEM ON (S_INVENTORY."INV_ITEM_SK" = ITEM."I_ITEM_SK" AND ITEM."I_REC_END_DATE" IS NULL)
LEFT OUTER JOIN DATE_DIM ON (DATE_DIM."D_DATE_SK" = S_INVENTORY."INV_DATE_SK");
--Create PROCEDURE
CREATE OR REPLACE PROCEDURE output_message(message VARCHAR)
RETURNS VARCHAR NOT NULL
LANGUAGE SQL
AS
BEGIN
RETURN message;
END;
CALL output_message('Hello World');
--Function
create or replace function EMP_DB.PUBLIC.salary_for_employee(EMP_ID varchar)
returns table (EMPLOYEE_NAME varchar, SALARY numeric(11, 2))
as
$$
select top 1 EMPLOYEE_NAME, SALARY
from EMP_DB.PUBLIC.EMPLOYEES
where EMPLOYEE_ID = EMP_ID
$$
;
select * from table(EMP_DB.PUBLIC.SALARY_FOR_EMPLOYEE('3'));
--End Of Object CreationStep 2: Get Source Objects Structure
Use the following command to download the source object structure in CSV or TSV format:
Select get_ddl('DATABASE','POC_DB');Caution: Provide the schema name “POC_SCHEMA” as a prefix for tables accessed in views. The Get_DDL function does not add that prefix. Also, check for case-sensitive column names and table names.
Step 3: Use ChatGPT for Conversion
Now, utilize ChatGPT to convert the Snowflake DDLs into SQL Server-compatible DDLs. If you’re using ChatGPT for the first time, sign up here.
Use the prompt “Convert the below Snowflake SQL code to T-SQL compatible SQL code” and copy-paste each DDL one at a time or all DDLs at once. You will receive a detailed output indicating the changes made in the resultant query.
Sample ChatGPT Output:
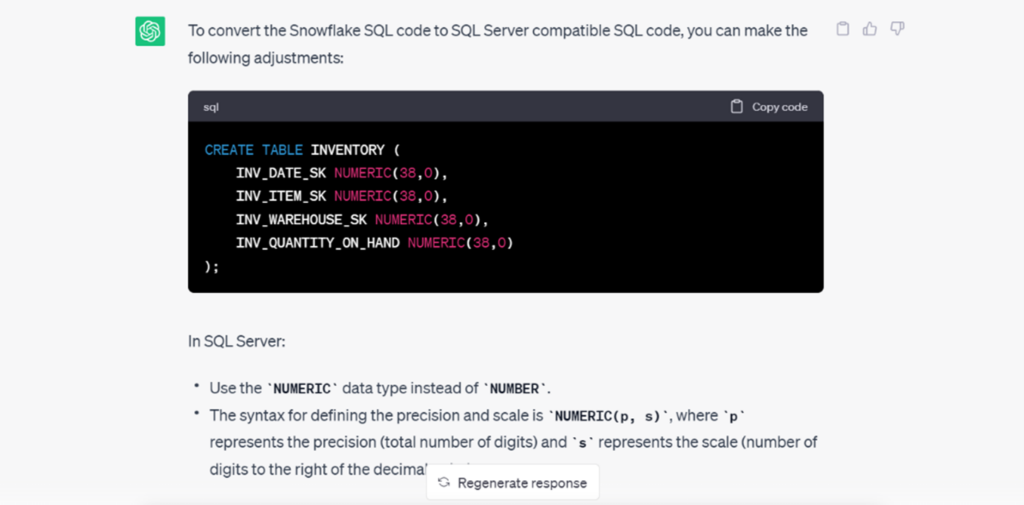
A Sample ChatGPT output script is attached herewith.
Open Microsoft Fabric and create a new warehouse or use an existing one. Create a new SQL query and run the converted SQL scripts to create the corresponding objects in the Fabric Data Warehouse.
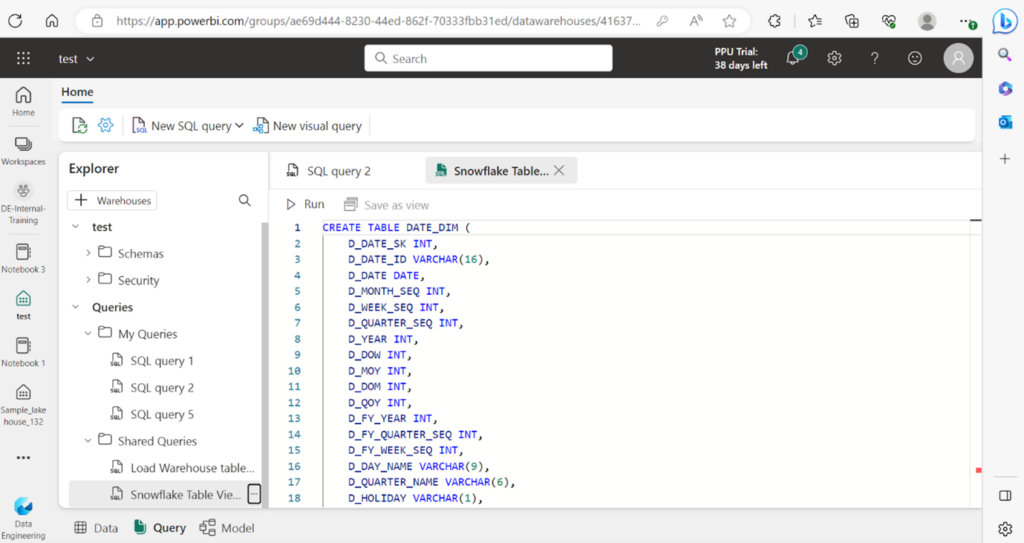
All tables, views, and SQL stored procedures will be created using this approach.
Part 2: Copy Data
Additional Prerequisites:
- S3 bucket
- IAM User with Access Key/Secret Key.
Data Copying Steps:
Step 1: Unload Snowflake Tables to S3 Bucket
There are various ways to copy or move data from Snowflake to Microsoft Fabric. In this demo, we’ll follow the conventional approach of unloading data from Snowflake and then copying it into Fabric. My snowflake account is hosted on AWS & unloading data from Snowflake to cloud provider where its hosted is seamless, cheap & fast.
To unload Snowflake tables onto an external stage, you’ll need an S3 bucket and IAM user credentials. Run the following unload commands on Snowsight console within snowflake account to move Snowflake data to the S3 bucket:
COPY INTO 's3://poc-snowflake-171003/files/warehouse/'
FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.warehouse
CREDENTIALS = (AWS_KEY_ID='XXXXXXX' AWS_SECRET_KEY='XXXXXXX')
FILE_FORMAT = (TYPE = PARQUET) overwrite =TRUE;
COPY INTO 's3://poc-snowflake-171003/files/date_dim/'
FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.date_dim
CREDENTIALS = (AWS_KEY_ID='XXXXXXX' AWS_SECRET_KEY='XXXXXXX')
FILE_FORMAT = (TYPE = PARQUET);
COPY INTO 's3://poc-snowflake-171003/files/ITEM/'
FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.ITEM
CREDENTIALS = (AWS_KEY_ID='XXXXXXX' AWS_SECRET_KEY='XXXXXXX')
FILE_FORMAT = (TYPE = PARQUET);
COPY INTO 's3://poc-snowflake-171003/files/INVENTORY/'
FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.INVENTORY
CREDENTIALS = (AWS_KEY_ID='XXXXXXX' AWS_SECRET_KEY='XXXXXXX')
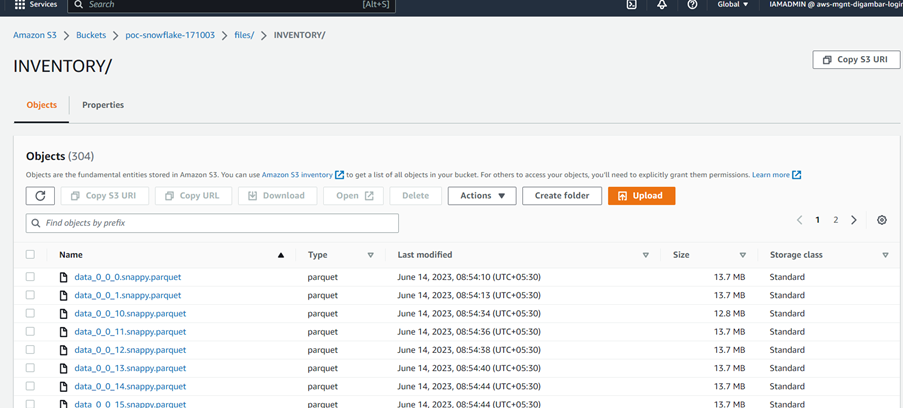
FILE_FORMAT = (TYPE = PARQUET)Screenshot showing S3 Bucket where snowflake data is unloaded.
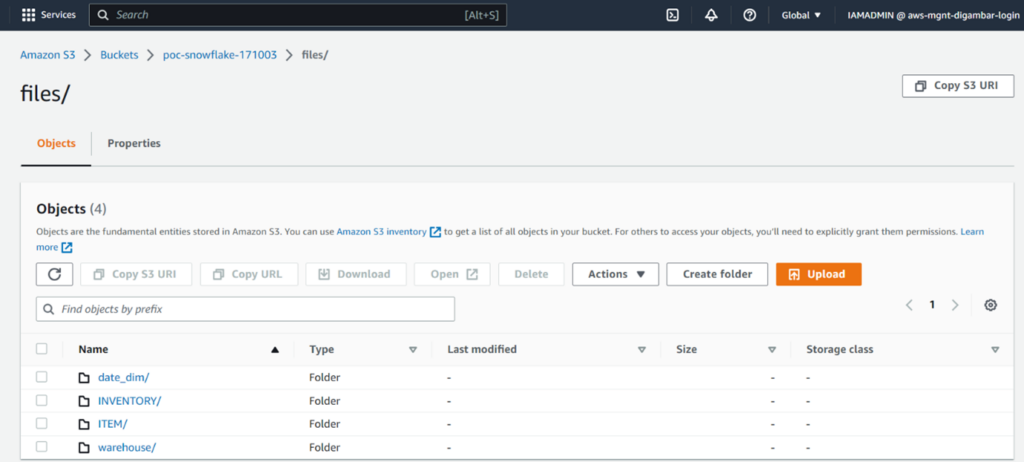
Screenshot showing parquet data files unloaded for Inventory table.
Step 2: Create a Lakehouse & S3 Shortcut in Microsoft Fabric
Steps to create a lakehouse
- Sign in to Microsoft Fabric.
- Switch to the Data Engineering experience using the experience switcher icon at the lower left corner of your homepage.
- Select Workspaces from the left-hand menu.
- To open your workspace, enter its name in the search textbox located at the top and select it from the search results.
- In the upper left corner of the workspace home page, select New and then choose Lakehouse.
- Give your lakehouse a name and select Create.
- A new lakehouse is created and if this is your first OneLake item, OneLake is provisioned behind the scenes.
What are Fabric shortcuts
Shortcuts in Microsoft OneLake allow you to unify your data across domains, clouds, and accounts by creating a single virtual data lake for your entire enterprise
Create an Amazon S3 shortcut
Prerequisites
If you don’t have a lakehouse, create one by following these steps: Creating a lakehouse with OneLake.
Ensure your chosen S3 bucket and IAM user meet the access and authorization requirements for S3 shortcuts.
Steps:
- Open a lakehouse.
- Right-click on a directory within the Lake view of the lakehouse.
- Select New shortcut.Under External sources, select Amazon S3.
- Enter the Connection settings like Access Key, Secreat keys etc.
- Enter a name for your shortcut.
- Select Create.
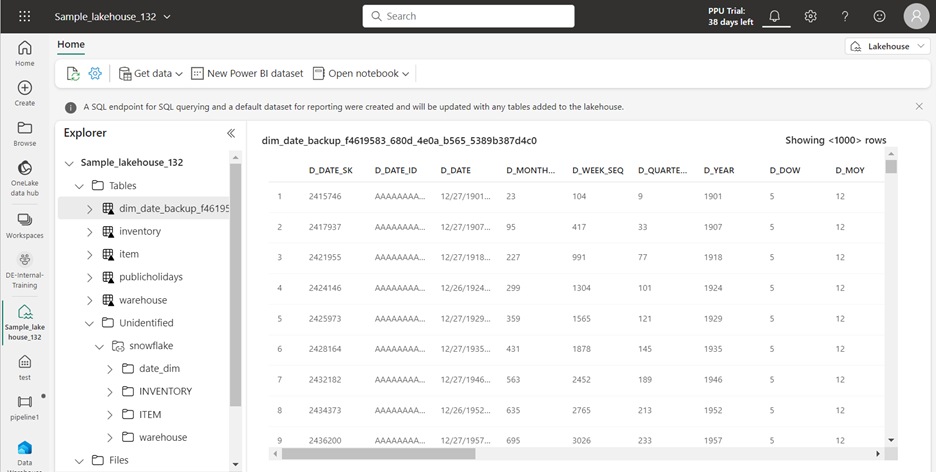
- The lakehouse automatically refreshes. The shortcut appears under Files in the Explorer pane
Create an S3 shortcut within Fabric Lakehouse to access the S3 location where the files have been unloaded.
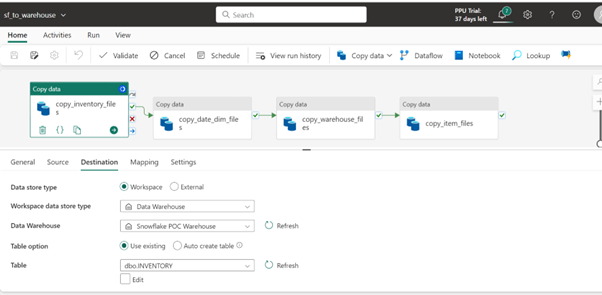
Step 3: Copy Data to Microsoft Fabric
Use a Fabric notebook or Fabric Data Factory pipeline copy activity to copy data from the S3 shortcut into the Fabric Warehouse tables.
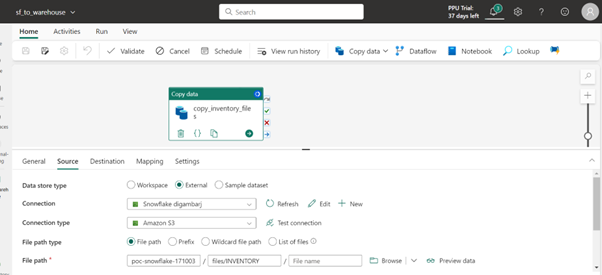
Screenshot showcasing Copy Activity Source Connections
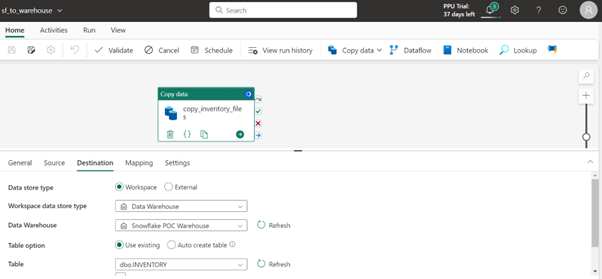
Screenshot showcasing Copy Activity Destination Connections
Screenshot showcasing Copy Activity Execution details
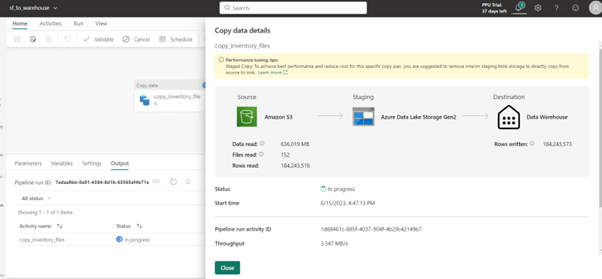
Screenshot showcasing one copy activity for each table in sequence
Conclusion:
This demonstration serves as a foundational proof of concept, offering a glimpse into the preliminary stages of a comprehensive migration project. Should you require expert guidance or assistance in executing a full-scale migration, we invite you to reach out to our technical team for personalized support and solutions.
Get Started
Explore a seamless transition from Snowflake data warehouse to Microsoft Fabric with our expert assistance. Contact us to learn more about our comprehensive data migration solutions.
Your data transformation journey starts here!

