Citizen Developers Can Scale & Work with IT Pros Like Never Before with Microsoft Fabric

When Microsoft Fabric reached General Availability (GA) in November last year, we shared our initial experience pioneering this platform across a variety of scenarios, concluding that “there’s a different Fabric for each use case.” With the rise of Real Time Intelligence highlighted during Build last May, Fabric showed even more versatility across a wide range of industries, organization sizes, and functional requirements.
As we publish this from the FabCon Europe conference in Stockholm, six months after the initial FabCon Vegas, we’re getting close to one year into GA and the dust is starting to settle. If you take a step back from technology, all our Fabric projects have something in common. Or rather someone, as the common factor is human rather than technical.
What Fabric does that no other data platform had accomplished yet is to bring ALL user personas to truly collaborate in one place, across the entire analytics journey. From business users who live in Excel and PowerPoint, to Power BI data modeling afficionados, to seasoned data engineers and scientists, we can finally all work together, as well as understand and appreciate better what everyone else is contributing.
We’ve seen too many large organizations suffer from disconnects between their various teams, with poor shared understanding of their respective needs and challenges. No matter how great the individual parts are, somehow the sum ends up being less than the parts. Fabric solves that friction. Let’s start by looking at it from the perspective of regular business users.
Tap Into Your Business Knowledge & Conquer the Learning Curve
Power BI’s initial success came in large part from the fact it’s an approachable reporting tool for business users coming from an Excel background. But reporting needs clean and structured data. Unfortunately, getting to that stage often remained a bottleneck for people trying to solve their data problems by themselves. Dataflows Gen1 and Datamarts did add self-service data transformation and warehousing to the Power BI platform, but they came with performance and functional limitations that put a glass ceiling on top of solutions developed by power users. Meanwhile, Power BI’s native orchestration capabilities were limited and often required adding tools such as Power Automate.
With Microsoft Fabric, these somewhat arbitrary limitations are lifted with accessible yet fully scalable orchestration, ETL/ELT, and lakehouse/warehouse tooling. To start, Data Factory pipelines bring not only a no-code scheduler to the Power BI world, but also make fast copy activities very easy. That includes retrieving data from REST APIs which used to require complicated manual work using Power Query.
In combination with Pipelines, Dataflows Gen2 come with better materialization options than their predecessors, making them a more versatile and open solution for easy data transformations. They’re also catching up with incremental refresh capabilities that were so far missing. Meanwhile, the lakehouse and warehouse SQL endpoints have built-in graphical user interfaces (GUIs) and copilot-based T-SQL code generation. You can start using SQL without being a full-blown database administrator, and there’s even a new T-SQL notebook where you can explore and document your findings.
For the most demanding jobs, Data Wrangler combines a no-code GUI reminiscent of Power Query with the scalability and performance of the Apache Spark engine. This, combined with the matching copilot, will ease many more people into learning Python by tweaking generated code rather than starting from an intimidating blank page. You know where else there’s also a copilot that generates Python code? Excel, the tool that you’ll never pry out of the hands of business users. It makes even more sense for them to get on a gentle learning path and become able to use what’s arguably the most popular language in the data analytics world.
With Fabric, citizen developers are able to take their homegrown solutions further before requiring help from dedicated data engineers, if they need it at all. And if they do require help, the pros won’t have to throw away everything and start again in a completely different tool. Business users can capture their requirements by building something, not just talking about it, and sustaining it sometimes for years by themselves. If they do want IT support eventually, pro developers will be able to take it from there and add more robust practices such as continuous integration and development.
Explore More Ambitious Use Cases Before You Need to Call the Cavalry
Covering the end-to-end journey from data ingestion to reporting would be a great value proposition by itself, but Fabric offers so much more than that. Your Power BI semantic models and reports are no longer the end of the data journey, but rather the core of a larger architecture. The semantic model is typically where business logic is added to make full sense of actuals so that past data can be sliced and diced by dimension. But what about descriptive and prescriptive analytics? How do you add value on top of your past data so that you’re not limited to watching a rear-view mirror? Power BI alone is a read-only proposition with limited options for advanced analytics or actionable reporting.
With Fabric, two new complementary patterns are available:
- Manual data entry of forecasts and drivers can be performed with tools such as Lumel Inforiver and ValQ, which work as native apps on Fabric and can seamlessly capture input from Power BI visuals and save it into OneLake, with almost-instant recursive feedback in the host report.
- With Semantic Link, you can also consume semantic models using Pyspark where you’ll generate a forecast, regression analysis, or countless other analytics payloads. This new data can then be saved into OneLake and be consumed back into the original semantic model. Not only can you now easily compare actuals, forecasts, budgets, and other series, but you can also keep track of forecasting accuracy in one place.

These integrated capabilities make Microsoft Fabric, in combination with natively-hosted ISVs, a contender worthy of consideration in the FP&A/xP&A category (Financial / Expanded Planning & Analysis) which has traditionally been dominated by expensive proprietary solutions with long implementation cycles. We have also been successful in using Fabric for intricate analytics requirements that were previously tackled by developing custom data apps for a much higher cost.
Data Modeling & Engineering Finally Together
Many organizations end up with a sizable gap between their data engineering teams, who might optimize for speed and maintainability on one hand, and BI data modelers on the other hand who have very specific requirements centered around dimensional modeling and star schemas. When the BI side receives data that’s still in third normal form or has been flattened into wide tables, they end up resorting to crutches that scale poorly, like using Power Query way beyond its intended scale or resorting to DAX calculated tables. This is a costly mistake.
Data modelers should be the internal clients of data engineers, but it’s easier said than done when different teams use completely different toolsets. By bringing them under one roof, collaboration becomes easier to pursue. The gold layer in a lakehouse should be custom built to conform with semantic modeling best practices. This is now easier to achieve thanks to the tight integration between each of Fabric’s workloads. It will take time for the market to fully realize and internalize this, and there will be some internal resistance and turf battles in some places for sure, but this is a big win.

Our Recommendations
While Fabric can be used for a top-down, IT centric approach, it would be a missed opportunity not to tap its potential for true collaboration and deep involvement from business stakeholders who typically like to contribute to solving their data challenges. After all, they know their data, and they know what they want to get out of it.
Federated approaches like the data mesh pattern seek to reconcile data governance and cost management considerations on one hand, with agility and responsiveness on the other hand. Leaders who want to make the most of their investments as well as catch the Generative AI wave should pay close attention to organizational design, not just technology platform choices.
Fabric is evolving at a pace not seen since Power BI’s early days almost a decade ago, which gives confidence that it will not just soon match its on-premises and Platform As A Service predecessors wherever there are still gaps – data source connectors come to mind – but also eventually supersede them with not just a much broader feature set, but perhaps more importantly at a much higher degree of integration. Fabric is a massive, long-term investment for Microsoft. Ignore it at your own peril!
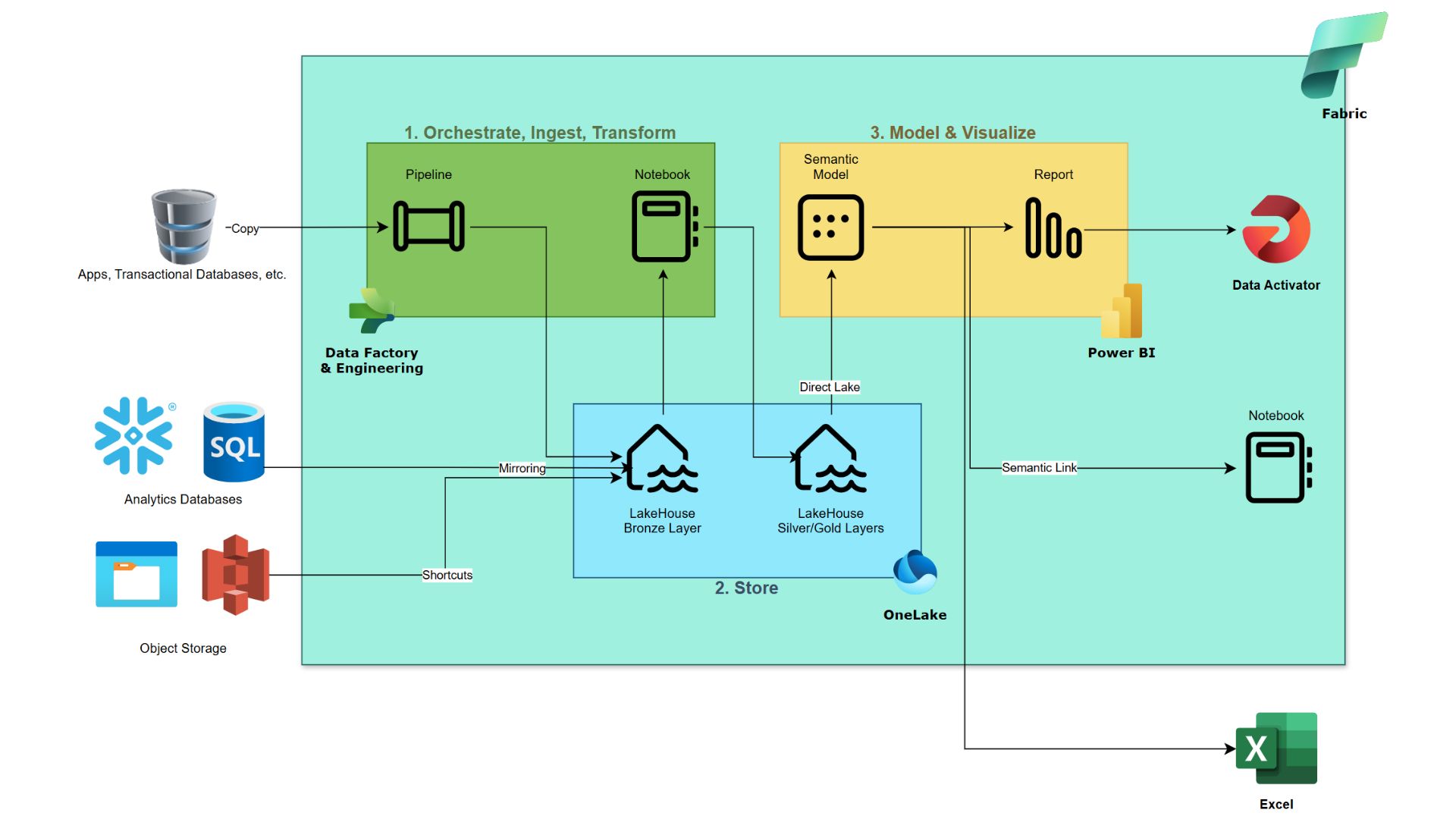
For the purpose of readability, we’re presenting as a conclusion a simplified reference architecture for Fabric in the flowchart below. Is this an abstraction that hides some moving parts such as data gateways or the real-time part of the stack? Of course, we’ll readily admit that a detailed technical architecture will be a bit more complex. And we didn’t put icons for copilots because, well, they’re everywhere! But this visual remains a truthful skeleton of what many Fabric implementations will look like at a high level. Simple and integrated is the point, and everyone will benefit from Fabric’s streamlined approach.